Project - Recommendation Systems: Movie Recommendation System
Marks: 40
Context
Online streaming platforms like Netflix have plenty of movies in their repository and if we can build a Recommendation System to recommend relevant movies to users, based on their historical interactions, this would improve customer satisfaction and hence, it will also improve the revenue of the platform. The techniques that we will learn here will not only be limited to movies, it can be any item for which you want to build a recommendation system.
Objective
In this project we will be building various recommendation systems:
- Knowledge/Rank based recommendation system
- Similarity-Based Collaborative filtering
- Matrix Factorization Based Collaborative Filtering
we are going to use the ratings dataset.
Dataset
The ratings dataset contains the following attributes:
- userId
- movieId
- rating
- timestamp
Sometimes, the installation of the surprise library, which is used to build recommendation systems, faces issues in Jupyter. To avoid any issues, it is advised to use Google Colab for this case study.
Let’s start by mounting the Google drive on Colab.
# uncomment if you are using google colab
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
Installing surprise library
# Installing surprise library, only do it for first time
!pip install surprise
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting surprise
Downloading surprise-0.1-py2.py3-none-any.whl (1.8 kB)
Collecting scikit-surprise
Downloading scikit-surprise-1.1.3.tar.gz (771 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m772.0/772.0 kB[0m [31m12.4 MB/s[0m eta [36m0:00:00[0m
[?25h Preparing metadata (setup.py) ... [?25l[?25hdone
Requirement already satisfied: joblib>=1.0.0 in /usr/local/lib/python3.9/dist-packages (from scikit-surprise->surprise) (1.2.0)
Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.9/dist-packages (from scikit-surprise->surprise) (1.22.4)
Requirement already satisfied: scipy>=1.3.2 in /usr/local/lib/python3.9/dist-packages (from scikit-surprise->surprise) (1.10.1)
Building wheels for collected packages: scikit-surprise
Building wheel for scikit-surprise (setup.py) ... [?25l[?25hdone
Created wheel for scikit-surprise: filename=scikit_surprise-1.1.3-cp39-cp39-linux_x86_64.whl size=3195832 sha256=8f3babac20ecd6bc40c9d8f4d366c5014960af1be5c00488b81dcb0a28c0888b
Stored in directory: /root/.cache/pip/wheels/c6/3a/46/9b17b3512bdf283c6cb84f59929cdd5199d4e754d596d22784
Successfully built scikit-surprise
Installing collected packages: scikit-surprise, surprise
Successfully installed scikit-surprise-1.1.3 surprise-0.1
Importing the necessary libraries and overview of the dataset
# Used to ignore the warning given as output of the code
import warnings
warnings.filterwarnings('ignore')
# Basic libraries of python for numeric and dataframe computations
import numpy as np
import pandas as pd
# Basic library for data visualization
import matplotlib.pyplot as plt
# Slightly advanced library for data visualization
import seaborn as sns
# A dictionary output that does not raise a key error
from collections import defaultdict
# A performance metrics in surprise
from surprise import accuracy
# Class is used to parse a file containing ratings, data should be in structure - user ; item ; rating
from surprise.reader import Reader
# Class for loading datasets
from surprise.dataset import Dataset
# For model tuning model hyper-parameters
from surprise.model_selection import GridSearchCV
# For splitting the rating data in train and test dataset
from surprise.model_selection import train_test_split
# For implementing similarity based recommendation system
from surprise.prediction_algorithms.knns import KNNBasic
# For implementing matrix factorization based recommendation system
from surprise.prediction_algorithms.matrix_factorization import SVD
# For implementing cross validation
from surprise.model_selection import KFold
Loading the data
# Import the dataset
#rating = pd.read_csv('ratings.csv')
rating = pd.read_csv('/content/drive/MyDrive/ratings.csv') # Uncomment this line code and comment above line of code if you are using google colab.
Let’s check the info of the data
rating.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100004 entries, 0 to 100003
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 userId 100004 non-null int64
1 movieId 100004 non-null int64
2 rating 100004 non-null float64
3 timestamp 100004 non-null int64
dtypes: float64(1), int64(3)
memory usage: 3.1 MB
- There are 1,00,004 observations and 4 columns in the data
- All the columns are of numeric data type
- The data type of the timestamp column is int64 which is not correct. We can convert this to DateTime format but we don’t need timestamp for our analysis. Hence, we can drop this column
# Dropping timestamp column
rating = rating.drop(['timestamp'], axis=1)
Question 1: Exploring the dataset (7 Marks)
Let’s explore the dataset and answer some basic data-related questions:
###Q 1.1 Print the top 5 rows of the dataset (1 Mark)
# Printing the top 5 rows of the dataset Hint: use .head()
# Remove _______and complete the code
rating.head()
| userId | movieId | rating | |
|---|---|---|---|
| 0 | 1 | 31 | 2.5 |
| 1 | 1 | 1029 | 3.0 |
| 2 | 1 | 1061 | 3.0 |
| 3 | 1 | 1129 | 2.0 |
| 4 | 1 | 1172 | 4.0 |
Q 1.2 Describe the distribution of ratings. (1 Mark)
plt.figure(figsize = (12, 4))
# Remove _______and complete the code
sns.countplot(x="rating", data=rating)
plt.tick_params(labelsize = 10)
plt.title("Distribution of Ratings ", fontsize = 10)
plt.xlabel("Ratings", fontsize = 10)
plt.ylabel("Number of Ratings", fontsize = 10)
plt.show()
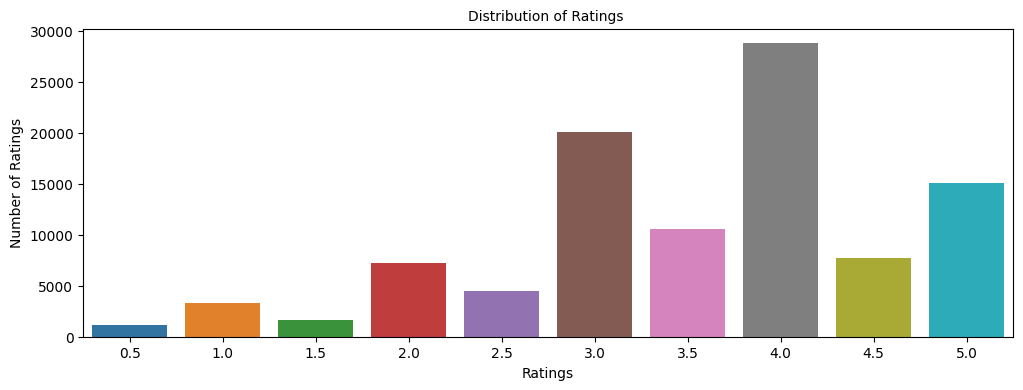
Write your Answer here:
The highest counts of ratings are for integer ratings. The highest is for rating 4.0 (>25k), followed by rating 3.0 (∼20k) and 5.0 (∼15k). The distribution is left-skewed. There are more high ratings than very low ratings.
Q 1.3 What is the total number of unique users and unique movies? (1 Mark)
# Finding number of unique users
#remove _______ and complete the code
rating['userId'].nunique()
671
Write your answer here:
There are 671 unique users.
# Finding number of unique movies
# Remove _______ and complete the code
rating['movieId'].nunique()
9066
Write your answer here:
There are 9066 unique movies.
Q 1.4 Is there a movie in which the same user interacted with it more than once? (1 Mark)
rating.groupby(['userId', 'movieId']).count()
| rating | ||
|---|---|---|
| userId | movieId | |
| 1 | 31 | 1 |
| 1029 | 1 | |
| 1061 | 1 | |
| 1129 | 1 | |
| 1172 | 1 | |
| ... | ... | ... |
| 671 | 6268 | 1 |
| 6269 | 1 | |
| 6365 | 1 | |
| 6385 | 1 | |
| 6565 | 1 |
100004 rows × 1 columns
rating.groupby(['userId', 'movieId']).count()['rating'].sum()
100004
Write your Answer here:
No, there is no movie where the same user interact with it more than once, because the sum of ratings (100004) is the same as the total number of user-movie interactions.
Q 1.5 Which is the most interacted movie in the dataset? (1 Mark)
# Remove _______ and complete the code
rating['movieId'].value_counts()
356 341
296 324
318 311
593 304
260 291
...
98604 1
103659 1
104419 1
115927 1
6425 1
Name: movieId, Length: 9066, dtype: int64
Write your Answer here:
The movie with id 356 is the most interacted movie in the dataset with 341 ratings. This number is just a fraction of the 671 unique users. 671-341= 330 users could still interact with that movie.
# Plotting distributions of ratings for 341 interactions with movieid 356
plt.figure(figsize=(7,7))
rating[rating['movieId'] == 356]['rating'].value_counts().plot(kind='bar')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.show()
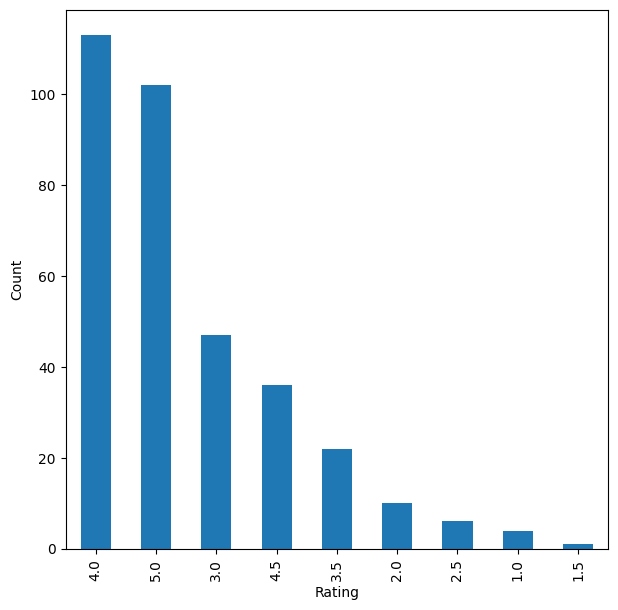
Write your Answer here:______
Q 1.6 Which user interacted the most with any movie in the dataset? (1 Mark)
# Remove _______ and complete the code
rating['userId'].value_counts()
547 2391
564 1868
624 1735
15 1700
73 1610
...
296 20
289 20
249 20
221 20
1 20
Name: userId, Length: 671, dtype: int64
Write your Answer here:
The user with id 547 interacted the most with 2391 movies in the dataset.
Q 1.7 What is the distribution of the user-movie interactions in this dataset? (1 Mark)
# Finding user-movie interactions distribution
count_interactions = rating.groupby('userId').count()['movieId']
count_interactions
userId
1 20
2 76
3 51
4 204
5 100
...
667 68
668 20
669 37
670 31
671 115
Name: movieId, Length: 671, dtype: int64
# Plotting user-movie interactions distribution
plt.figure(figsize=(15,7))
# Remove _______ and complete the code
sns.histplot(count_interactions)
plt.xlabel('Number of Interactions by Users')
plt.show()
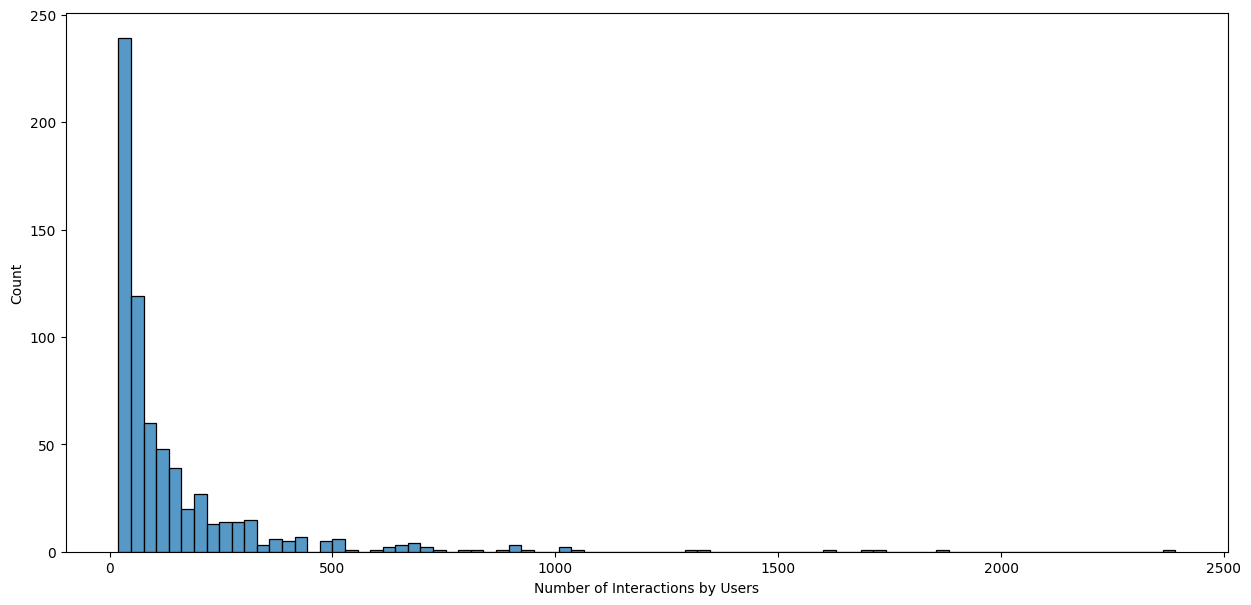
Write your Answer here:
The distribution of user-movie interactions is very right-skewed. Most of the users interacted with less than 200 movies and very few with more than 500 movies.
As we have now explored the data, let’s start building Recommendation systems
Question 2: Create Rank-Based Recommendation System (3 Marks)
Model 1: Rank-Based Recommendation System
Rank-based recommendation systems provide recommendations based on the most popular items. This kind of recommendation system is useful when we have cold start problems. Cold start refers to the issue when we get a new user into the system and the machine is not able to recommend movies to the new user, as the user did not have any historical interactions in the dataset. In those cases, we can use rank-based recommendation system to recommend movies to the new user.
To build the rank-based recommendation system, we take average of all the ratings provided to each movie and then rank them based on their average rating.
# Remove _______ and complete the code
# Calculating average ratings
average_rating = rating.groupby('movieId').mean()['rating']
# Calculating the count of ratings
count_rating = rating.groupby('movieId').count()['rating']
# Making a dataframe with the count and average of ratings
final_rating = pd.DataFrame({'avg_rating':average_rating, 'rating_count':count_rating})
final_rating.head()
| avg_rating | rating_count | |
|---|---|---|
| movieId | ||
| 1 | 3.872470 | 247 |
| 2 | 3.401869 | 107 |
| 3 | 3.161017 | 59 |
| 4 | 2.384615 | 13 |
| 5 | 3.267857 | 56 |
Now, let’s create a function to find the top n movies for a recommendation based on the average ratings of movies. We can also add a threshold for a minimum number of interactions for a movie to be considered for recommendation.
def top_n_movies(data, n, min_interaction=100):
#Finding movies with minimum number of interactions
recommendations = data[data['rating_count'] >= min_interaction]
#Sorting values w.r.t average rating
recommendations = recommendations.sort_values(by='avg_rating', ascending=False)
return recommendations.index[:n]
We can use this function with different n’s and minimum interactions to get movies to recommend
Recommending top 5 movies with 50 minimum interactions based on popularity
# Remove _______ and complete the code
list(top_n_movies(final_rating, 5, 50))
[858, 318, 969, 913, 1221]
Recommending top 5 movies with 100 minimum interactions based on popularity
# Remove _______ and complete the code
list(top_n_movies(final_rating, 5, 100))
[858, 318, 1221, 50, 527]
Recommending top 5 movies with 200 minimum interactions based on popularity
# Remove _______ and complete the code
list(top_n_movies(final_rating, 5, 200))
[858, 318, 50, 527, 608]
Now that we have seen how to apply the Rank-Based Recommendation System, let’s apply the Collaborative Filtering Based Recommendation Systems.
Model 2: User based Collaborative Filtering Recommendation System (7 Marks)

In the above interactions matrix, out of users B and C, which user is most likely to interact with the movie, “The Terminal”?
In this type of recommendation system, we do not need any information about the users or items. We only need user item interaction data to build a collaborative recommendation system. For example -
- Ratings provided by users. For example - ratings of books on goodread, movie ratings on imdb etc
- Likes of users on different facebook posts, likes on youtube videos
- Use/buying of a product by users. For example - buying different items on e-commerce sites
- Reading of articles by readers on various blogs
Types of Collaborative Filtering
-
Similarity/Neighborhood based
- User-User Similarity Based
-
Item-Item similarity based
- Model based
Building Similarity/Neighborhood based Collaborative Filtering

Building a baseline user-user similarity based recommendation system
- Below, we are building similarity-based recommendation systems using
cosinesimilarity and using KNN to find similar users which are the nearest neighbor to the given user. - We will be using a new library, called
surprise, to build the remaining models. Let’s first import the necessary classes and functions from this library.
Below we are loading the rating dataset, which is a pandas DataFrame, into a different format called surprise.dataset.DatasetAutoFolds, which is required by this library. To do this, we will be using the classes Reader and Dataset. Finally splitting the data into train and test set.
Making the dataset into surprise dataset and splitting it into train and test set
# Instantiating Reader scale with expected rating scale
reader = Reader(rating_scale=(0, 5))
# Loading the rating dataset
data = Dataset.load_from_df(rating[['userId', 'movieId', 'rating']], reader)
# Splitting the data into train and test dataset
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
Build the first baseline similarity based recommendation system using cosine similarity and KNN
# Remove _______ and complete the code
# Defining Nearest neighbour algorithm
sim_options = {'name': 'cosine', 'user_based': True}
algo_knn_user = KNNBasic(sim_options=sim_options, verbose=False)
# Train the algorithm on the trainset or fitting the model on train dataset
algo_knn_user.fit(trainset)
# Predict ratings for the testset
predictions = algo_knn_user.test(testset)
# Then compute RMSE
accuracy.rmse(predictions)
RMSE: 0.9925
0.9924509041520163
Q 3.1 What is the RMSE for baseline user based collaborative filtering recommendation system? (1 Mark)
Write your Answer here:
On test set the baseline user based collaborative filtering recommandation system has RMSE≈0.99.
Q 3.2 What is the Predicted rating for an user with userId=4 and for movieId=10 and movieId=3? (1 Mark)
Let’s us now predict rating for an user with userId=4 and for movieId=10
# Remove _______ and complete the code
algo_knn_user.predict(4, 10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 3.62 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=3.6244912065910952, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
User with id 4 has already interacted with movie with id 10 with a rating of 4.0. The estimated rating from this recommendation system is 3.62.
Let’s predict the rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3
# Remove _______ and complete the code
algo_knn_user.predict(4, 3, verbose=True)
user: 4 item: 3 r_ui = None est = 3.20 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=3.202703552548654, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
User with id 4 has not interacted yet with movie with id 3. The estimated rating coming from this recommendation system is 3.20.
Improving user-user similarity based recommendation system by tuning its hyper-parameters
Below we will be tuning hyper-parmeters for the KNNBasic algorithms. Let’s try to understand different hyperparameters of KNNBasic algorithm -
- k (int) – The (max) number of neighbors to take into account for aggregation (see this note). Default is 40.
- min_k (int) – The minimum number of neighbors to take into account for aggregation. If there are not enough neighbors, the prediction is set to the global mean of all ratings. Default is 1.
- sim_options (dict) – A dictionary of options for the similarity measure. And there are four similarity measures available in surprise -
- cosine
- msd (default)
- pearson
- pearson baseline
For more details please refer the official documentation https://surprise.readthedocs.io/en/stable/knn_inspired.html
Q 3.3 Perform hyperparameter tuning for the baseline user based collaborative filtering recommendation system and find the RMSE for tuned user based collaborative filtering recommendation system? (3 Marks)
# Remove _______ and complete the code
# Setting up parameter grid to tune the hyperparameters
param_grid = {'k': [20,30,40], 'min_k': [1,3,6,9], 'sim_options': {'name':['msd','cosine'], 'user_based':[True]}}
# Performing 3-fold cross validation to tune the hyperparameters
grid_obj = GridSearchCV(KNNBasic, param_grid, measures=['rmse', 'mae'], cv=3, n_jobs=-1)
# Fitting the data
grid_obj.fit(data)
# Best RMSE score
print(grid_obj.best_score['rmse'])
# Combination of parameters that gave the best RMSE score
print(grid_obj.best_params['rmse'])
0.965646132311634
{'k': 20, 'min_k': 3, 'sim_options': {'name': 'msd', 'user_based': True}}
Once the grid search is complete, we can get the optimal values for each of those hyperparameters as shown above.
Below we are analysing evaluation metrics - RMSE and MAE at each and every split to analyze the impact of each value of hyperparameters
results_df = pd.DataFrame.from_dict(grid_obj.cv_results)
results_df.head()
| split0_test_rmse | split1_test_rmse | split2_test_rmse | mean_test_rmse | std_test_rmse | rank_test_rmse | split0_test_mae | split1_test_mae | split2_test_mae | mean_test_mae | std_test_mae | rank_test_mae | mean_fit_time | std_fit_time | mean_test_time | std_test_time | params | param_k | param_min_k | param_sim_options | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.978240 | 0.975281 | 0.975510 | 0.976344 | 0.001344 | 8 | 0.750479 | 0.747570 | 0.748425 | 0.748825 | 0.001221 | 6 | 0.104516 | 0.002837 | 2.726556 | 0.035860 | {'k': 20, 'min_k': 1, 'sim_options': {'name': ... | 20 | 1 | {'name': 'msd', 'user_based': True} |
| 1 | 1.005711 | 1.003892 | 1.002947 | 1.004183 | 0.001147 | 24 | 0.775955 | 0.774435 | 0.773293 | 0.774561 | 0.001091 | 24 | 0.214824 | 0.018782 | 2.719341 | 0.030162 | {'k': 20, 'min_k': 1, 'sim_options': {'name': ... | 20 | 1 | {'name': 'cosine', 'user_based': True} |
| 2 | 0.963572 | 0.965565 | 0.967802 | 0.965646 | 0.001728 | 1 | 0.742218 | 0.741581 | 0.743573 | 0.742457 | 0.000831 | 1 | 0.212198 | 0.051202 | 4.262047 | 1.046854 | {'k': 20, 'min_k': 3, 'sim_options': {'name': ... | 20 | 3 | {'name': 'msd', 'user_based': True} |
| 3 | 0.990955 | 0.994063 | 0.995241 | 0.993420 | 0.001808 | 17 | 0.767455 | 0.768192 | 0.768272 | 0.767973 | 0.000368 | 15 | 0.247518 | 0.017589 | 2.738646 | 0.015598 | {'k': 20, 'min_k': 3, 'sim_options': {'name': ... | 20 | 3 | {'name': 'cosine', 'user_based': True} |
| 4 | 0.967522 | 0.968595 | 0.970320 | 0.968812 | 0.001153 | 3 | 0.745046 | 0.743944 | 0.745736 | 0.744909 | 0.000738 | 2 | 0.128241 | 0.026238 | 3.353801 | 0.889977 | {'k': 20, 'min_k': 6, 'sim_options': {'name': ... | 20 | 6 | {'name': 'msd', 'user_based': True} |
Now, let’s build the final model by using tuned values of the hyperparameters, which we received by using grid search cross-validation.
# Remove _______ and complete the code
# Using the optimal similarity measure for user-user based collaborative filtering
# Creating an instance of KNNBasic with optimal hyperparameter values
sim_options = {'name': 'msd', 'user_based': True}
similarity_algo_optimized_user = KNNBasic(sim_options=sim_options, k=20, min_k=3,verbose=False)
# Training the algorithm on the trainset
similarity_algo_optimized_user.fit(trainset)
# Predicting ratings for the testset
predictions = similarity_algo_optimized_user.test(testset)
# Computing RMSE on testset
accuracy.rmse(predictions)
RMSE: 0.9571
0.9571445417153293
Write your Answer here:
The tuned user based collaborative filtering recommandation system has RMSE≈0.96. Compared to the baseline system (RMSE≈0.99) the RMSE has decreased. Therefore, after hyperparameter tuning the system has been improved.
Q 3.4 What is the Predicted rating for an user with userId =4 and for movieId= 10 and movieId=3 using tuned user based collaborative filtering? (1 Mark)
Let’s us now predict rating for an user with userId=4 and for movieId=10 with the optimized model
# Remove _______ and complete the code
similarity_algo_optimized_user.predict(4,10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 3.74 {'actual_k': 20, 'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=3.740028692988536, details={'actual_k': 20, 'was_impossible': False})
Write your Answer here:
User with id 4 has already interacted with movie with id 10 with a rating of 4.0. The estimated rating from this tuned user based recommendation system is 3.74, better than the estimated rating from the baseline system (3.62).
Below we are predicting rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3, by using the optimized model as shown below -
# # Remove _______ and complete the code
similarity_algo_optimized_user.predict(4,3, verbose=True)
user: 4 item: 3 r_ui = None est = 3.72 {'actual_k': 20, 'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=3.7228745701935386, details={'actual_k': 20, 'was_impossible': False})
Write your Answer here:
User with id 4 has not interacted yet with movie with id 3. The estimated rating coming from the tuned user based recommendation system is 3.72. With the baseline system the estimated rating is 3.20.
Identifying similar users to a given user (nearest neighbors)
We can also find out the similar users to a given user or its nearest neighbors based on this KNNBasic algorithm. Below we are finding 5 most similar user to the userId=4 based on the msd distance metric
similarity_algo_optimized_user.get_neighbors(4, k=5)
[665, 417, 647, 654, 260]
Implementing the recommendation algorithm based on optimized KNNBasic model
Below we will be implementing a function where the input parameters are -
- data: a rating dataset
- user_id: an user id against which we want the recommendations
- top_n: the number of movies we want to recommend
- algo: the algorithm we want to use to predict the ratings
def get_recommendations(data, user_id, top_n, algo):
# Creating an empty list to store the recommended movie ids
recommendations = []
# Creating an user item interactions matrix
user_item_interactions_matrix = data.pivot(index='userId', columns='movieId', values='rating')
# Extracting those movie ids which the user_id has not interacted yet
non_interacted_movies = user_item_interactions_matrix.loc[user_id][user_item_interactions_matrix.loc[user_id].isnull()].index.tolist()
# Looping through each of the movie id which user_id has not interacted yet
for item_id in non_interacted_movies:
# Predicting the ratings for those non interacted movie ids by this user
est = algo.predict(user_id, item_id).est
# Appending the predicted ratings
recommendations.append((item_id, est))
# Sorting the predicted ratings in descending order
recommendations.sort(key=lambda x: x[1], reverse=True)
return recommendations[:top_n] # returing top n highest predicted rating movies for this user
Predicted top 5 movies for userId=4 with similarity based recommendation system
#remove _______ and complete the code
recommendations = get_recommendations(rating, 4, 5, similarity_algo_optimized_user)
Q 3.5 Predict the top 5 movies for userId=4 with similarity based recommendation system (1 Mark)
recommendations
[(309, 5),
(3038, 5),
(6273, 4.928202652354184),
(98491, 4.863224466679252),
(2721, 4.845513973527148)]
Model 3: Item based Collaborative Filtering Recommendation System (7 Marks)
# Remove _______ and complete the code
# Definfing similarity measure
sim_options = {'name': 'cosine',
'user_based': False}
# Defining Nearest neighbour algorithm
algo_knn_item = KNNBasic(sim_options=sim_options,verbose=False)
# Train the algorithm on the trainset or fitting the model on train dataset
algo_knn_item.fit(trainset)
# Predict ratings for the testset
predictions = algo_knn_item.test(testset)
# Then compute RMSE
accuracy.rmse(predictions)
RMSE: 1.0032
1.003221450633729
Q 4.1 What is the RMSE for baseline item based collaborative filtering recommendation system ?(1 Mark)
Write your Answer here:
On the test set the baseline item based collaborative filtering recommendation system has RMSE≈1.00.
Let’s us now predict rating for an user with userId=4 and for movieId=10
Q 4.2 What is the Predicted rating for an user with userId =4 and for movieId= 10 and movieId=3? (1 Mark)
# Remove _______ and complete the code
algo_knn_item.predict(4,10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 4.37 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=4.373794871885004, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
User with id 4 has already interacted with movie with id 10 with a rating of 4.0. The estimated rating from this recommendation system is 4.37.
Let’s predict the rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3
# Remove _______ and complete the code
algo_knn_item.predict(4,3, verbose=True)
user: 4 item: 3 r_ui = None est = 4.07 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=4.071601862880049, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
User with id 4 has not interacted yet with movie with id 3. The estimated rating from this recommendation system is 4.07.
Q 4.3 Perform hyperparameter tuning for the baseline item based collaborative filtering recommendation system and find the RMSE for tuned item based collaborative filtering recommendation system? (3 Marks)
# Remove _______ and complete the code
# Setting up parameter grid to tune the hyperparameters
param_grid = {'k': [20,30,40], 'min_k': [1,3,6,9], 'sim_options': {'name':['msd','cosine'], 'user_based':[False]}}
# Performing 3-fold cross validation to tune the hyperparameters
grid_obj = GridSearchCV(KNNBasic, param_grid, measures=['rmse', 'mae'], cv=3, n_jobs=-1)
# Fitting the data
grid_obj.fit(data)
# Best RMSE score
print(grid_obj.best_score['rmse'])
# Combination of parameters that gave the best RMSE score
print(grid_obj.best_params['rmse'])
0.9396898494196343
{'k': 40, 'min_k': 3, 'sim_options': {'name': 'msd', 'user_based': False}}
Once the grid search is complete, we can get the optimal values for each of those hyperparameters as shown above
Below we are analysing evaluation metrics - RMSE and MAE at each and every split to analyze the impact of each value of hyperparameters
results_df = pd.DataFrame.from_dict(grid_obj.cv_results)
results_df.head()
| split0_test_rmse | split1_test_rmse | split2_test_rmse | mean_test_rmse | std_test_rmse | rank_test_rmse | split0_test_mae | split1_test_mae | split2_test_mae | mean_test_mae | std_test_mae | rank_test_mae | mean_fit_time | std_fit_time | mean_test_time | std_test_time | params | param_k | param_min_k | param_sim_options | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.948193 | 0.951402 | 0.952476 | 0.950690 | 0.001819 | 10 | 0.731816 | 0.734507 | 0.734481 | 0.733601 | 0.001263 | 9 | 4.235982 | 0.619689 | 15.547943 | 2.610945 | {'k': 20, 'min_k': 1, 'sim_options': {'name': ... | 20 | 1 | {'name': 'msd', 'user_based': False} |
| 1 | 1.011516 | 1.014836 | 1.012522 | 1.012958 | 0.001390 | 22 | 0.789859 | 0.791114 | 0.789257 | 0.790077 | 0.000774 | 21 | 7.637552 | 1.670468 | 16.183732 | 3.388851 | {'k': 20, 'min_k': 1, 'sim_options': {'name': ... | 20 | 1 | {'name': 'cosine', 'user_based': False} |
| 2 | 0.948333 | 0.950857 | 0.952367 | 0.950519 | 0.001664 | 9 | 0.732038 | 0.734334 | 0.734687 | 0.733686 | 0.001174 | 10 | 4.401310 | 0.473360 | 15.770335 | 1.387262 | {'k': 20, 'min_k': 3, 'sim_options': {'name': ... | 20 | 3 | {'name': 'msd', 'user_based': False} |
| 3 | 1.011642 | 1.014368 | 1.012477 | 1.012829 | 0.001140 | 21 | 0.790074 | 0.790992 | 0.789489 | 0.790185 | 0.000619 | 22 | 6.292680 | 0.540871 | 12.983727 | 0.218869 | {'k': 20, 'min_k': 3, 'sim_options': {'name': ... | 20 | 3 | {'name': 'cosine', 'user_based': False} |
| 4 | 0.948333 | 0.951057 | 0.953210 | 0.950867 | 0.001996 | 11 | 0.732084 | 0.734551 | 0.735015 | 0.733883 | 0.001287 | 11 | 4.428361 | 1.679174 | 19.724888 | 3.229316 | {'k': 20, 'min_k': 6, 'sim_options': {'name': ... | 20 | 6 | {'name': 'msd', 'user_based': False} |
Now let’s build the final model by using tuned values of the hyperparameters which we received by using grid search cross-validation.
# Remove _______ and complete the code
# Creating an instance of KNNBasic with optimal hyperparameter values
similarity_algo_optimized_item = KNNBasic(sim_options={'name': 'msd', 'user_based': False}, k=40, min_k=3,verbose=False)
# Training the algorithm on the trainset
similarity_algo_optimized_item.fit(trainset)
# Predicting ratings for the testset
predictions = similarity_algo_optimized_item.test(testset)
# Computing RMSE on testset
accuracy.rmse(predictions)
RMSE: 0.9433
0.9433184999641279
Write your Answer here:
The tuned item based collaborative filtering recommandation system has RMSE≈0.94. Compared to the baseline system (RMSE≈1.00) the RMSE has decreased. Therefore, after hyperparameter tuning the system has been improved.
Q 4.4 What is the Predicted rating for an item with userId =4 and for movieId= 10 and movieId=3 using tuned item based collaborative filtering? (1 Mark)
Let’s us now predict rating for an user with userId=4 and for movieId=10 with the optimized model as shown below
# Remove _______ and complete the code
similarity_algo_optimized_item.predict(4,10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 4.26 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=4.255054787154994, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
The estimated rating from this tuned item based recommendation system is 4.26, better than the estimated rating from the baseline system (4.37).
Let’s predict the rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3, by using the optimized model:
# Remove _______ and complete the code
similarity_algo_optimized_item.predict(4, 3, verbose=True)
user: 4 item: 3 r_ui = None est = 3.87 {'actual_k': 40, 'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=3.865175609312417, details={'actual_k': 40, 'was_impossible': False})
Write your Answer here:
The estimated rating coming from the tuned item based recommendation system is 3.87. With the baseline system the estimated rating is 4.07.
Identifying similar items to a given item (nearest neighbors)
We can also find out the similar items to a given item or its nearest neighbors based on this KNNBasic algorithm. Below we are finding 5 most similar items to the movieId=3 based on the msd distance metric
# Remove _______ and complete the code
similarity_algo_optimized_item.get_neighbors(3, k=5)
[31, 37, 42, 48, 73]
Predicted top 5 movies for userId=4 with similarity based recommendation system
# Remove _______ and complete the code
recommendations = get_recommendations(rating, 4, 5, similarity_algo_optimized_item)
Q 4.5 Predict the top 5 movies for userId=4 with similarity based recommendation system (1 Mark)
recommendations
[(84, 5), (1040, 5), (2481, 5), (3078, 5), (3116, 5)]
Model 4: Based Collaborative Filtering - Matrix Factorization using SVD (7 Marks)
Model-based Collaborative Filtering is a personalized recommendation system, the recommendations are based on the past behavior of the user and it is not dependent on any additional information. We use latent features to find recommendations for each user.
Latent Features: The features that are not present in the empirical data but can be inferred from the data. For example:

Now if we notice the above movies closely:

Here Action, Romance, Suspense and Comedy are latent features of the corresponding movies. Similarly, we can compute the latent features for users as shown below:

Singular Value Decomposition (SVD)
SVD is used to compute the latent features from the user-item matrix. But SVD does not work when we miss values in the user-item matrix.
First we need to convert the below movie-rating dataset:
into an user-item matrix as shown below:

We have already done this above while computing cosine similarities.
SVD decomposes this above matrix into three separate matrices:
- U matrix
- Sigma matrix
- V transpose matrix
U-matrix

the above matrix is a n x k matrix, where:
- n is number of users
- k is number of latent features
Sigma-matrix

the above matrix is a k x k matrix, where:
- k is number of latent features
- Each diagonal entry is the singular value of the original interaction matrix
V-transpose matrix

the above matrix is a kxn matrix, where:
- k is the number of latent features
- n is the number of items
Build a baseline matrix factorization recommendation system
# Remove _______ and complete the code
# Using SVD matrix factorization
algo_svd = SVD()
# Training the algorithm on the trainset
algo_svd.fit(trainset)
# Predicting ratings for the testset
predictions = algo_svd.test(testset)
# Computing RMSE on the testset
accuracy.rmse(predictions)
RMSE: 0.9029
0.9029014689887866
Q 5.1 What is the RMSE for baseline SVD based collaborative filtering recommendation system? (1 Mark)
Write your Answer here:
The baseline SVD based collaborative filtering recommendation system has a RMSE≈0.90 on the test set. This is the lowest RMSE that we have encountered so far: it is less than the tuned user based collaborative filtering recommendation system (RMSE≈0.96) and the tuned item based collaborative filtering recommendation system (RMSE≈0.94).
Q 5.2 What is the Predicted rating for an user with userId =4 and for movieId= 10 and movieId=3? (1 Mark)
Let’s us now predict rating for an user with userId=4 and for movieId=10
# Remove _______ and complete the code
algo_svd.predict(4, 10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 4.00 {'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=4.004509633308034, details={'was_impossible': False})
Write your Answer here:
The true rating is 4.0. The estimated one is basically the same as the true one (4.0).
Let’s predict the rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3:
# Remove _______ and complete the code
algo_svd.predict(4, 3, verbose=True)
user: 4 item: 3 r_ui = None est = 3.96 {'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=3.9616820359367093, details={'was_impossible': False})
Write your Answer here:
The estimated rating for movie with id 3 is 3.96 with the use of the baseline SVD based collaborative filtering recommendation system.
Improving matrix factorization based recommendation system by tuning its hyper-parameters
In SVD, rating is predicted as -
\[\hat{r}_{u i}=\mu+b_{u}+b_{i}+q_{i}^{T} p_{u}\]If user $u$ is unknown, then the bias $b_{u}$ and the factors $p_{u}$ are assumed to be zero. The same applies for item $i$ with $b_{i}$ and $q_{i}$.
To estimate all the unknown, we minimize the following regularized squared error:
\[\sum_{r_{u i} \in R_{\text {train }}}\left(r_{u i}-\hat{r}_{u i}\right)^{2}+\lambda\left(b_{i}^{2}+b_{u}^{2}+\left\|q_{i}\right\|^{2}+\left\|p_{u}\right\|^{2}\right)\]The minimization is performed by a very straightforward stochastic gradient descent:
\[\begin{aligned} b_{u} & \leftarrow b_{u}+\gamma\left(e_{u i}-\lambda b_{u}\right) \\ b_{i} & \leftarrow b_{i}+\gamma\left(e_{u i}-\lambda b_{i}\right) \\ p_{u} & \leftarrow p_{u}+\gamma\left(e_{u i} \cdot q_{i}-\lambda p_{u}\right) \\ q_{i} & \leftarrow q_{i}+\gamma\left(e_{u i} \cdot p_{u}-\lambda q_{i}\right) \end{aligned}\]There are many hyperparameters to tune in this algorithm, you can find a full list of hyperparameters here
Below we will be tuning only three hyperparameters -
- n_epochs: The number of iteration of the SGD algorithm
- lr_all: The learning rate for all parameters
- reg_all: The regularization term for all parameters
Q 5.3 Perform hyperparameter tuning for the baseline SVD based collaborative filtering recommendation system and find the RMSE for tuned SVD based collaborative filtering recommendation system? (3 Marks)
# Remove _______ and complete the code
# Set the parameter space to tune
param_grid = {'n_epochs': [10, 20, 30], 'lr_all': [0.001, 0.005, 0.01],
'reg_all': [0.2, 0.4, 0.6]}
# Performing 3-fold gridsearch cross validation
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3, n_jobs=-1)
# Fitting data
gs.fit(data)
# Best RMSE score
print(gs.best_score['rmse'])
# Combination of parameters that gave the best RMSE score
print(gs.best_params['rmse'])
0.8943041060540651
{'n_epochs': 30, 'lr_all': 0.01, 'reg_all': 0.2}
Once the grid search is complete, we can get the optimal values for each of those hyperparameters, as shown above.
Below we are analysing evaluation metrics - RMSE and MAE at each and every split to analyze the impact of each value of hyperparameters
results_df = pd.DataFrame.from_dict(gs.cv_results)
results_df.head()
| split0_test_rmse | split1_test_rmse | split2_test_rmse | mean_test_rmse | std_test_rmse | rank_test_rmse | split0_test_mae | split1_test_mae | split2_test_mae | mean_test_mae | std_test_mae | rank_test_mae | mean_fit_time | std_fit_time | mean_test_time | std_test_time | params | param_n_epochs | param_lr_all | param_reg_all | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.947087 | 0.935991 | 0.947257 | 0.943445 | 0.005271 | 25 | 0.739996 | 0.734454 | 0.740324 | 0.738258 | 0.002693 | 25 | 1.040736 | 0.298807 | 0.651955 | 0.134450 | {'n_epochs': 10, 'lr_all': 0.001, 'reg_all': 0.2} | 10 | 0.001 | 0.2 |
| 1 | 0.951797 | 0.940151 | 0.951333 | 0.947760 | 0.005384 | 26 | 0.745714 | 0.739233 | 0.745168 | 0.743372 | 0.002935 | 26 | 1.590924 | 0.074432 | 0.766977 | 0.223881 | {'n_epochs': 10, 'lr_all': 0.001, 'reg_all': 0.4} | 10 | 0.001 | 0.4 |
| 2 | 0.956860 | 0.945245 | 0.956954 | 0.953020 | 0.005498 | 27 | 0.751177 | 0.744883 | 0.751591 | 0.749217 | 0.003069 | 27 | 0.853958 | 0.054258 | 0.439016 | 0.034506 | {'n_epochs': 10, 'lr_all': 0.001, 'reg_all': 0.6} | 10 | 0.001 | 0.6 |
| 3 | 0.909925 | 0.900115 | 0.912273 | 0.907437 | 0.005266 | 10 | 0.704079 | 0.699159 | 0.704628 | 0.702622 | 0.002459 | 9 | 0.848723 | 0.064738 | 0.461821 | 0.033696 | {'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.2} | 10 | 0.005 | 0.2 |
| 4 | 0.917267 | 0.906880 | 0.919373 | 0.914507 | 0.005461 | 15 | 0.712158 | 0.706661 | 0.712466 | 0.710428 | 0.002667 | 15 | 0.825620 | 0.024862 | 0.436168 | 0.013312 | {'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4} | 10 | 0.005 | 0.4 |
Now, we will the build final model by using tuned values of the hyperparameters, which we received using grid search cross-validation above.
# Remove _______ and complete the code
# Building the optimized SVD model using optimal hyperparameter search
svd_algo_optimized = SVD(n_epochs=30, lr_all=0.01, reg_all=0.2)
# Training the algorithm on the trainset
svd_algo_optimized.fit(trainset)
# Predicting ratings for the testset
predictions = svd_algo_optimized.test(testset)
# Computing RMSE
accuracy.rmse(predictions)
RMSE: 0.8955
0.895453182598101
Q 5.4 What is the Predicted rating for an user with userId =4 and for movieId= 10 and movieId=3 using SVD based collaborative filtering? (1 Mark)
Let’s us now predict rating for an user with userId=4 and for movieId=10 with the optimized model
# Remove _______ and complete the code
svd_algo_optimized.predict(4, 10, r_ui=4, verbose=True)
user: 4 item: 10 r_ui = 4.00 est = 3.99 {'was_impossible': False}
Prediction(uid=4, iid=10, r_ui=4, est=3.986677913286987, details={'was_impossible': False})
Write your Answer here:
The estimated rating for movie with id 10 is 3.99. It is basically the same as the true one (4.0).
Let’s predict the rating for the same userId=4 but for a movie which this user has not interacted before i.e. movieId=3:
# Remove _______ and complete the code
svd_algo_optimized.predict(4, 3, verbose=True)
user: 4 item: 3 r_ui = None est = 3.63 {'was_impossible': False}
Prediction(uid=4, iid=3, r_ui=None, est=3.6287192073193566, details={'was_impossible': False})
Q 5.5 Predict the top 5 movies for userId=4 with SVD based recommendation system?(1 Mark)
# Remove _______ and complete the code
get_recommendations(rating, 4, 5, svd_algo_optimized)
[(1192, 5),
(116, 4.951504150667473),
(926, 4.9486031091710005),
(5114, 4.943015803442837),
(3310, 4.9267735930685035)]
Predicting ratings for already interacted movies
Below we are comparing the rating predictions of users for those movies which has been already watched by an user. This will help us to understand how well are predictions are as compared to the actual ratings provided by users
def predict_already_interacted_ratings(data, user_id, algo):
# Creating an empty list to store the recommended movie ids
recommendations = []
# Creating an user item interactions matrix
user_item_interactions_matrix = data.pivot(index='userId', columns='movieId', values='rating')
# Extracting those movie ids which the user_id has interacted already
interacted_movies = user_item_interactions_matrix.loc[user_id][user_item_interactions_matrix.loc[user_id].notnull()].index.tolist()
# Looping through each of the movie id which user_id has interacted already
for item_id in interacted_movies:
# Extracting actual ratings
actual_rating = user_item_interactions_matrix.loc[user_id, item_id]
# Predicting the ratings for those non interacted movie ids by this user
predicted_rating = algo.predict(user_id, item_id).est
# Appending the predicted ratings
recommendations.append((item_id, actual_rating, predicted_rating))
# Sorting the predicted ratings in descending order
recommendations.sort(key=lambda x: x[1], reverse=True)
return pd.DataFrame(recommendations, columns=['movieId', 'actual_rating', 'predicted_rating']) # returing top n highest predicted rating movies for this user
Here we are comparing the predicted ratings by similarity based recommendation system against actual ratings for userId=7
predicted_ratings_for_interacted_movies = predict_already_interacted_ratings(rating, 7, similarity_algo_optimized_item)
df = predicted_ratings_for_interacted_movies.melt(id_vars='movieId', value_vars=['actual_rating', 'predicted_rating'])
sns.displot(data=df, x='value', hue='variable', kde=True);
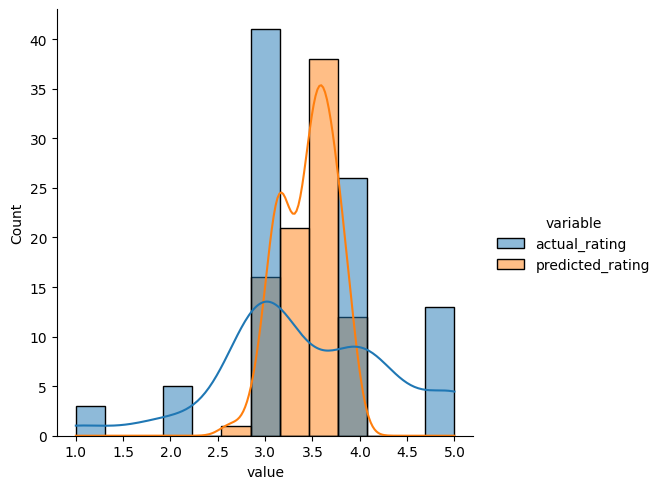
Write your Answer here:
For user 7 the distribution of the predicted ratings by the tuned item based recommendation system is more centered on the most common actual ratings (3.0 and 4.0). Most of the predicted ratings are between 3.0 and 4.0. They are in a continuous range while the actual ratings are discreet. This is because the predicted values are obtained by aggregating the ratings from the nearest neighbors of user 7.
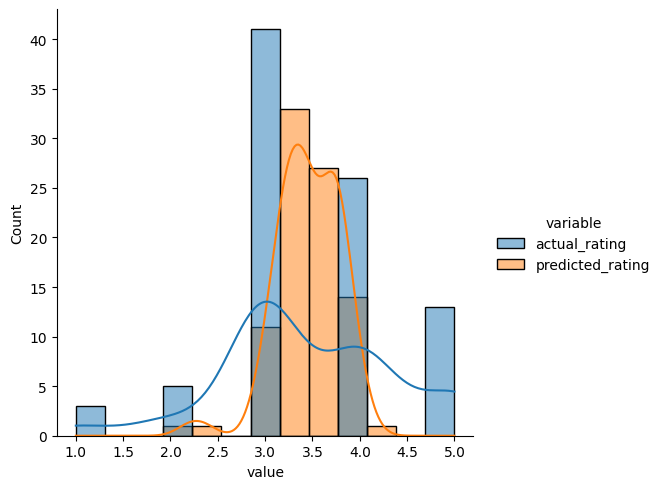
Below we are comparing the predicted ratings by matrix factorization based recommendation system against actual ratings for userId=7
predicted_ratings_for_interacted_movies = predict_already_interacted_ratings(rating, 7, svd_algo_optimized)
df = predicted_ratings_for_interacted_movies.melt(id_vars='movieId', value_vars=['actual_rating', 'predicted_rating'])
sns.displot(data=df, x='value', hue='variable', kde=True);
# Instantiating Reader scale with expected rating scale
reader = Reader(rating_scale=(0, 5))
# Loading the rating dataset
data = Dataset.load_from_df(rating[['userId', 'movieId', 'rating']], reader)
# Splitting the data into train and test dataset
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
Precision and Recall @ k
RMSE is not the only metric we can use here. We can also examine two fundamental measures, precision and recall. We also add a parameter k which is helpful in understanding problems with multiple rating outputs.
Precision@k - It is the fraction of recommended items that are relevant in top k predictions. Value of k is the number of recommendations to be provided to the user. One can choose a variable number of recommendations to be given to a unique user.
Recall@k - It is the fraction of relevant items that are recommended to the user in top k predictions.
Recall - It is the fraction of actually relevant items that are recommended to the user i.e. if out of 10 relevant movies, 6 are recommended to the user then recall is 0.60. Higher the value of recall better is the model. It is one of the metrics to do the performance assessment of classification models.
Precision - It is the fraction of recommended items that are relevant actually i.e. if out of 10 recommended items, 6 are found relevant by the user then precision is 0.60. The higher the value of precision better is the model. It is one of the metrics to do the performance assessment of classification models.
See the Precision and Recall @ k section of your notebook and follow the instructions to compute various precision/recall values at various values of k.
To know more about precision recall in Recommendation systems refer to these links :
https://surprise.readthedocs.io/en/stable/FAQ.html
https://medium.com/@m_n_malaeb/recall-and-precision-at-k-for-recommender-systems-618483226c54
Question6: Compute the precision and recall, for each of the 6 models, at k = 5 and 10. This is 6 x 2 = 12 numerical values? (4 marks)
# Function can be found on surprise documentation FAQs
def precision_recall_at_k(predictions, k=10, threshold=3.5):
"""Return precision and recall at k metrics for each user"""
# First map the predictions to each user.
user_est_true = defaultdict(list)
for uid, _, true_r, est, _ in predictions:
user_est_true[uid].append((est, true_r))
precisions = dict()
recalls = dict()
for uid, user_ratings in user_est_true.items():
# Sort user ratings by estimated value
user_ratings.sort(key=lambda x: x[0], reverse=True)
# Number of relevant items
n_rel = sum((true_r >= threshold) for (_, true_r) in user_ratings)
# Number of recommended items in top k
n_rec_k = sum((est >= threshold) for (est, _) in user_ratings[:k])
# Number of relevant and recommended items in top k
n_rel_and_rec_k = sum(((true_r >= threshold) and (est >= threshold))
for (est, true_r) in user_ratings[:k])
# Precision@K: Proportion of recommended items that are relevant
# When n_rec_k is 0, Precision is undefined. We here set it to 0.
precisions[uid] = n_rel_and_rec_k / n_rec_k if n_rec_k != 0 else 0
# Recall@K: Proportion of relevant items that are recommended
# When n_rel is 0, Recall is undefined. We here set it to 0.
recalls[uid] = n_rel_and_rec_k / n_rel if n_rel != 0 else 0
return precisions, recalls
# A basic cross-validation iterator.
kf = KFold(n_splits=5)
# Make list of k values
K = [5, 10]
# Remove _______ and complete the code
# Make list of models
models = [algo_knn_user, similarity_algo_optimized_user, algo_knn_item, similarity_algo_optimized_item, algo_svd, svd_algo_optimized]
for k in K:
for model in models:
print('> k={}, model={}'.format(k,model.__class__.__name__))
p = []
r = []
for trainset, testset in kf.split(data):
model.fit(trainset)
predictions = model.test(testset, verbose=False)
precisions, recalls = precision_recall_at_k(predictions, k=k, threshold=3.5)
# Precision and recall can then be averaged over all users
p.append(sum(prec for prec in precisions.values()) / len(precisions))
r.append(sum(rec for rec in recalls.values()) / len(recalls))
print('-----> Precision: ', round(sum(p) / len(p), 3))
print('-----> Recall: ', round(sum(r) / len(r), 3))
> k=5, model=KNNBasic
-----> Precision: 0.767
-----> Recall: 0.412
> k=5, model=KNNBasic
-----> Precision: 0.774
-----> Recall: 0.418
> k=5, model=KNNBasic
-----> Precision: 0.604
-----> Recall: 0.323
> k=5, model=KNNBasic
-----> Precision: 0.679
-----> Recall: 0.357
> k=5, model=SVD
-----> Precision: 0.748
-----> Recall: 0.384
> k=5, model=SVD
-----> Precision: 0.747
-----> Recall: 0.385
> k=10, model=KNNBasic
-----> Precision: 0.75
-----> Recall: 0.55
> k=10, model=KNNBasic
-----> Precision: 0.751
-----> Recall: 0.558
> k=10, model=KNNBasic
-----> Precision: 0.59
-----> Recall: 0.475
> k=10, model=KNNBasic
-----> Precision: 0.661
-----> Recall: 0.504
> k=10, model=SVD
-----> Precision: 0.733
-----> Recall: 0.517
> k=10, model=SVD
-----> Precision: 0.729
-----> Recall: 0.525
Question 7 ( 5 Marks)
7.1 Compare the results from the base line user-user and item-item based models.
7.2 How do these baseline models compare to each other with respect to the tuned user-user and item-item models?
7.3 The matrix factorization model is different from the collaborative filtering models. Briefly describe this difference. Also, compare the RMSE and precision recall for the models.
7.4 Does it improve? Can you offer any reasoning as to why that might be?
Write your Answer here:
- Baseline user-user based model (RMSE≈0.99) performs slightly better than the baseline item-item based model (RMSE≈1.00). Basically, the two have nearly the same performance for RMSE but in terms of precision and recall user-user based model performs better (precision 0.77 against 0.61, recall 0.41 against 0.33).
- Compared to the baseline models, the tuned user-user model performs better (RMSE 0.96 against 0.99); same for the tuned item-item model (RMSE 0.94 against 1.00). Then, between the tuned models the item-item model performs better in terms of RMSE but for precision and recall the tuned user-user model has a better performance (for example, for k=5, precision 0.77 against 0.68, recall 0.42 against 0.36 but we can find the same trend also for k=10).
- Collaborative Filtering model looks for similar item preferences among users and suggests items that their “neighbors” have interacted with. On the other hand, Matrix Factorization model works by breaking down the user-item matrix into two rectangular matrices of lower dimensionality. The RMSE of both baseline and tuned SVD model is more optimal than the collaborative filtering models: the baseline RMSE is 0.90, very close to the tuned RMSE (0.895). These values are the lowest compared to the all other RMSEs, even the lowest RMSE of the collaborative filtering is 0.94. Moreover, the SVD predicted rating of movie id 10 for user id 4 is so far the best we have encountered (3.99 against the actual rating of 4.0). However, in terms of precision and recall the SVD model performs better than the item-item based model but not the user-user based model: for example, for k=5, the precision of the tuned SVD model is 0.75, higher than tuned item-item based model (0.68) but still lower than tuned user-user model (0.77). We can find the same trend for k=10.
- Therefore, the SVD model improves only the RMSE metric but not precision and recall which are still the highest for the user-user base model. A possible reason why Matrix Factorization achieves a lower RMSE is that it operates under the assumption that both users and items can be represented in a lower-dimensional space that describes their properties. It then recommends items based on their proximity to the user in this latent space. However, it seems that the relevant recommended movies ratios are higher for the user-user model. Maybe, at least for this dataset, the latent space tends to reduce the value of the predicted ratings. Indeed, a major difference between the predicted ratings distributions we have plotted before is that the peak of the curve for the SVD model is lower than for the collaborative filtering model and SVD distribution has predicted values around 2 and 2.5 that do not appear in the other distribution. Hence, choosing the most optimal recommendation model will eventually depend on the business goals through which we can aim at a RMSE minimization or a precision and recall maximization.
Conclusions
In this case study, we saw three different ways of building recommendation systems:
- rank-based using averages
- similarity-based collaborative filtering
- model-based (matrix factorization) collaborative filtering
We also understood advantages/disadvantages of these recommendation systems and when to use which kind of recommendation systems. Once we build these recommendation systems, we can use A/B Testing to measure the effectiveness of these systems.
Here is an article explaining how Amazon use A/B Testing to measure effectiveness of its recommendation systems.